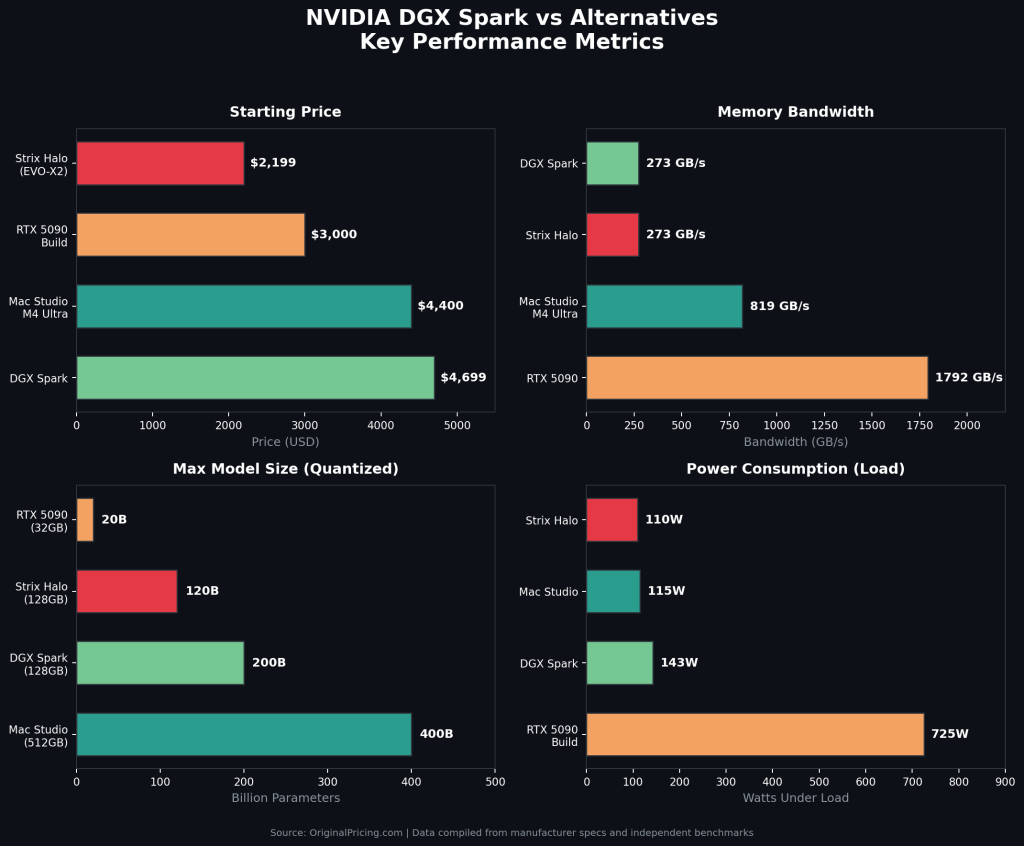
The NVIDIA DGX Spark ($3,999-$4,699) delivers 1 petaFLOP of FP4 AI compute and 128 GB of unified memory in a compact desktop. But it is not the only path to running large language models locally. The top alternatives include AMD Strix Halo mini PCs (starting around $2,199), Apple Mac Studio M4 Ultra ($4,400+), NVIDIA RTX 5090 custom builds ($2,800-$3,200), and multi-GPU configurations. Each trades off memory capacity, bandwidth, software ecosystem, and price differently.

Why People Look Beyond the DGX Spark?
The Spark landed with serious hype after its GTC 2025 announcement and October 2025 launch. Powered by the GB10 Grace Blackwell Superchip, it promised an AI lab in a box smaller than a Mac Mini.
But NVIDIA raised the MSRP from $3,999 to $4,699 in February 2026, citing LPDDR5x supply constraints. Memory bandwidth sits at just 273 GB/s, well below competing platforms. Thermal throttling under sustained load limits real-world throughput, with multiple reviewers documenting performance drops after 20-30 minutes of continuous operation.
Community reaction has been mixed. Forum posts on NVIDIA’s developer boards called out the price-to-performance ratio, noting that used GPU rigs or AMD APU systems offer better raw value. Others countered that the CES 2026 software update delivering 2.5x performance gains partially offsets the price increase.
The result is a genuinely complicated buying decision. The Spark is not the fastest, cheapest, or most versatile option in its class. But it occupies a unique niche at the intersection of CUDA compatibility, unified memory capacity, and compact form factor.
DGX Spark by the Numbers
- Price: $3,999 (launch) to $4,699 (current NVIDIA Marketplace)
- Compute: 1 PFLOP FP4 sparse (dense throughput is significantly lower)
- Memory: 128 GB unified LPDDR5x at 273 GB/s bandwidth
- Max model capacity: 200B parameters (inference), 70B (fine-tuning)
- Form factor: 150 x 150 mm, 1.2 kg, Linux only
- Software: Full CUDA stack, TensorRT-LLM, NeMo, Ollama pre-installed
For a broader look at how pricing shapes hardware decisions, explore our gaming console pricing history.
Head-to-Head Comparison
| Spec | DGX Spark | AMD Strix Halo | Mac Studio M4 | RTX 5090 Build |
| Price | $4,699 | $2,199-$2,950 | ~$4,400+ | ~$2,800-$3,200 |
| Memory | 128 GB unified | 128 GB unified | Up to 512 GB | 32 GB GDDR7 |
| Bandwidth | 273 GB/s | ~273 GB/s | 819 GB/s | 1,792 GB/s |
| Max Model Size | 200B params | ~120B (quant.) | 400B+ (quant.) | ~20B (FP16) |
| Software | CUDA, TensorRT | ROCm, HIP | Metal, MLX | CUDA, TensorRT |
| OS | Linux only | Linux/Windows | macOS only | Linux/Windows |
| Power (Load) | ~143W | ~100-120W | ~115W | 725W+ |
| Dimensions | 150 x 150 mm | Varies by OEM | 197 x 197 mm | Full ATX tower |

AMD Strix Halo: Best Value Alternative
AMD’s Ryzen AI Max+ 395 has emerged as the Spark’s most direct competitor. The Framework Desktop and GMKtec EVO-X2 pack 128 GB of unified memory at roughly half the price.
Token generation is surprisingly close: 34.13 tok/s versus the Spark’s 38.55 tok/s on 120B models. The real gap is prompt processing, where the Spark clocks 1,723 tok/s compared to Strix Halo’s 339.87 tok/s. If your workflow involves RAG pipelines or massive document ingestion, that 5x prefill advantage matters.
Strix Halo runs on ROCm instead of CUDA. The ecosystem is improving, but still lacks the depth of NVIDIA’s pre-built containers and enterprise tooling. It does run Windows natively, which the Linux-only Spark cannot. The price-to-performance math mirrors the dynamics we cover in our Steam Deck vs ROG Ally vs Legion Go comparison.
Apple Mac Studio M4 Ultra: Bandwidth Champion
The Mac Studio is the memory bandwidth king. With up to 512 GB at 819 GB/s, it offers roughly 3x the bandwidth of both the Spark and Strix Halo. That translates directly to faster token generation on large models. For 70B+ parameter inference at FP16, the Mac Studio is measurably faster than the Spark.
It also runs near-silently, drawing just 115W under load. For shared workspaces and home offices, the noise difference compared to a multi-GPU tower is significant.
The limitation is the software ecosystem. Metal and MLX frameworks lack CUDA compatibility. If your production deployment targets NVIDIA infrastructure, developing on a Mac introduces friction. An interesting workaround has emerged: pairing a Spark with a Mac Studio for disaggregated inference yields a 2.8x speedup.
For creators who also do AI work, the Mac Studio doubles as a creative workstation, something the Linux-only Spark cannot do. That dual-purpose value mirrors how the PS5 pricing factors in both gaming and media capabilities.
RTX 5090 Build: Raw Speed on a Budget
At $1,999-$2,200 for the GPU (total build around $2,800-$3,200), the RTX 5090 delivers 1,792 GB/s bandwidth, roughly 6.5x the Spark. For models fitting within 32 GB VRAM, nothing at this price touches it. It hits approximately 95 tok/s on Llama 3 8B and around 18 tok/s on Llama 3 70B (Q4 quantized).
Image generation is another strong suit. Running FLUX.1 Dev at full precision, the 5090 generates images roughly 2.5x faster than the Spark.
The hard ceiling is memory. At 32 GB, you cannot load anything above ~20B parameters at full precision. Quantized 70B models barely fit. Anything larger (DeepSeek R1, Nemotron 3 Super 120B) simply crashes. Power draw is also a factor at 725W+ under load. GPU pricing dynamics follow patterns similar to our RTX 5070 Ti pricing analysis. For multi-GPU setups (2-3x RTX 3090/4090), throughput per dollar improves further, but size, noise, and 1,000W+ power consumption push these into niche workstation territory.
Budget Entry Points
Not every AI workflow needs 128 GB of memory. The Mac Mini M4 Pro ($1,399-$1,599) handles 7B-13B models comfortably with 24 GB of unified memory, making it the best entry point for local AI on a budget. For even lighter workloads, AMD Ryzen 7-based mini PCs with 32 GB RAM can run quantized 7B models for basic inference at a fraction of the cost. Budget buyers comparing value across tech categories may find a similar dynamic in our guide to Kindle alternatives.
Questions People Actually Ask
Is the DGX Spark worth it over a gaming PC with an RTX 5090?
Only if you need models larger than 32 GB. For 8B-20B models, the 5090 is faster and cheaper. The Spark’s value is entirely in its 128 GB unified memory pool and pre-configured NVIDIA software stack.
Can I just use a Mac Studio instead?
For pure inference, yes, and it will often be faster thanks to higher memory bandwidth. But if your production stack depends on CUDA, TensorRT-LLM, or NeMo, the Spark avoids compatibility headaches when moving code to data center infrastructure.
What about cloud GPUs instead of buying hardware?
Cloud rental works for elastic workloads, but recurring costs add up fast for always-on inference. The Spark also keeps sensitive data on-premises, which matters for healthcare, legal, and finance teams handling private data.
Should I wait for the DGX Station?
The DGX Station targets a different tier entirely, with 784 GB of memory and expected pricing around $50,000+. The Spark is the entry-level product in NVIDIA’s personal AI lineup.
Common Mistakes When Choosing an Alternative
- Comparing PFLOP numbers directly: The Spark’s 1 PFLOP is FP4 sparse. Compare actual tok/s benchmarks, not marketing specs.
- Ignoring memory bandwidth: Capacity (how much you load) and bandwidth (how fast you read it) are different bottlenecks entirely.
- Assuming CUDA is always necessary: For inference-only workflows through Ollama or LM Studio, ROCm and Metal work fine.
- Overlooking power costs: A multi-GPU tower at 1,000W adds $700-$1,200/year in electricity.
- Buying memory you will not use: If your largest model is 13B, you do not need 128 GB. A $1,400 Mac Mini handles it.
- Skipping thermal research: The Spark throttles after 20-30 minutes of continuous load in its compact chassis.
Hardware pricing shifts across categories follow predictable patterns, as we have tracked with Xbox console pricing over time and Kindle alternative pricing.
Which Alternative Fits Your Workflow?
Choose the DGX Spark if you need CUDA ecosystem portability from desktop to data center. Code that runs on the Spark runs on DGX Station, DGX SuperPOD, and cloud NVIDIA instances with zero changes. That workflow did not exist at this price point before.
Choose Strix Halo if budget matters and ROCm is acceptable. Choose the Mac Studio if bandwidth, silent operation, and dual-purpose creative use are priorities. Choose an RTX 5090 build if you work primarily with sub-20B models and want maximum inference speed per dollar.
The Spark wins on no single metric, but it wins on the combination of memory capacity, form factor, and NVIDIA software ecosystem. For everything else, the alternatives deliver more value for their specific use cases.